Every business wants more data. Data on their customers, competition, operations, processes, employees, inventory and more. Data can be used to make better-informed business decisions and provide strategic insights that give your company a competitive advantage in terms of efficiencies, enhancing the customer experience, or refining market strategy. Its uses are limitless. Over the last decade, computing power has advanced to the point where generating and storing massive amounts of data has become highly cost efficient.
Up to 73% of data within an enterprise goes unused for analytics.
Amassing business data is similar to a dog successfully chasing a car – now that we’ve caught it, what do we do with it? With all that data available, most businesses struggle to figure out how to take advantage of it. According to Forrester, up to 73% of data within an enterprise goes unused for analytics. We are so used to extracting targeted information from data that we simply ignore what we don’t understand and throw it away as noise. This problem is prevalent in every industry, but especially in the security world. Security teams are overwhelmed with the vast amounts of data generated from firewalls, intrusion detection systems, network appliances and other devices. It’s impossible to expect security teams to interpret all this data. We unintentionally end up focusing on what we already know how to analyze and ignoring what we don’t.
Typical alerting systems are configured to raise alarms, but only when they encounter a defined binary event or a threshold being reached. For example, if three or more failed authentication attempts performed in succession are detected, the system is configured to generate an alert. Yet successful authentication attempts are mostly categorized as business as usual and ignored, even if they’re occuring at off times or from unexpected locations The current mean time to detect a breach is over six months. Most organizations have all the data they need to identify a breach much faster than that, yet they are still unable to detect and react to a breach in even a semi-reasonable amount of time. This is due to:
- The volume and velocity of the data being generated
- Not looking for patterns in all of the data available – the unknown unknowns
- Not having the proper context for the data available
If your system is ever breached, you don’t need to look at the failed authentication events – you need to look for anomalies in the successful ones!
Most organizations are well down the path on their journey of capturing and storing all of their data for future analytics in data Lakes, large repositories of raw data in any format. Capturing, storing and securing that data is key. Once the data is available, it can be analyzed and its value maximized using a variety of methods. This is where the fun (and benefit) starts!
On HPE NonStop servers, XYGATE Merged Audit (XMA) gathers, normalizes and stores security audit data from both the system and its applications. Merged Audit is your central repository for all NonStop security data. This is your NonStop Security Data Lake. In some environments, the data XMA gathers can amount to tens of millions of records per system, per day. With that kind of volume, you might think it’s nearly impossible to draw all of the value out of from this massive amount of data. This data can be fed to an external Security Information Event Manager (SIEM) or your Security Orchestration, Automation and Response (SOAR) solution for alerting, but most of it likely falls into that 73% that is treated as noise and does nothing but occupy disk space.
The Rise of the Machines
Machine learning is all the rage in the industry these days and there is no doubt vendors seek to capitalize on the hype. Unlike statistical analysis, used for decades to draw inferences about the relationships, machine learning is about the results and predictability of data. There are a variety of machine learning technologies. The availability of data lakes and massive computing power creates the unique opportunity and challenge of leveraging machine learning to its full potential. With the availability of large volumes of training data, Graphic Processing Units (GPUs) for fast computation of matrix operations, better activation functions and better architecture, it’s becoming far easier to construct and attempt to train the necessary deep networks for accurate machine learning. We’ll discuss two approaches on how to maximize the value of your data: Supervised and Unsupervised machine learning.
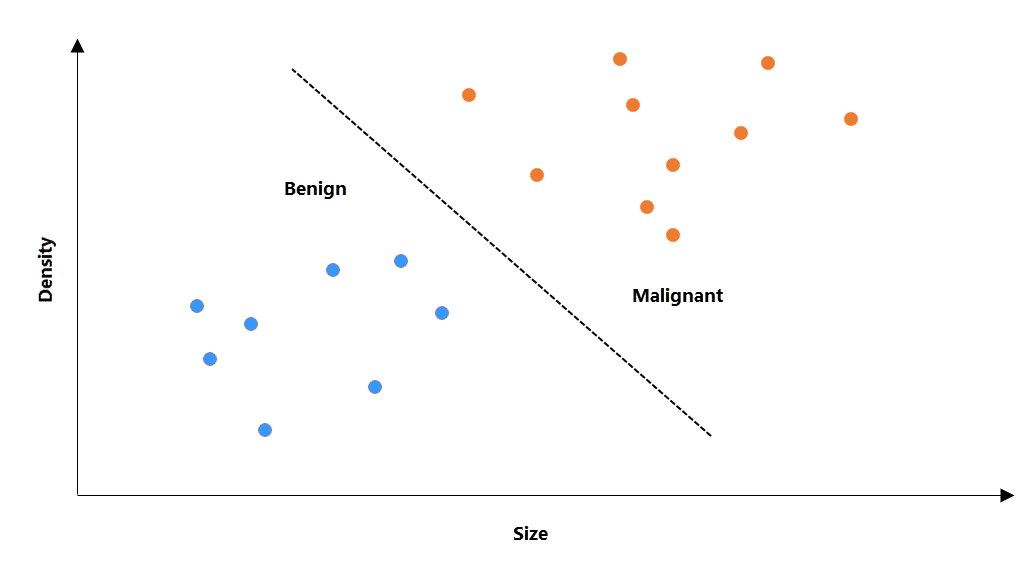
 Supervised Machine Learning algorithms apply what has been learned about data in the past to new inputs using labeled examples to predict future results. For example, in cancer diagnosis, a large amount of patient data is gathered regarding the characteristics of a tumor. Since we know which data inputs indicate a benign tumor and which are a malignant one based on a variety of factors, we could label the data as such. Then by simply knowing the cell density and tumor size of new patient inputs, we could predict if the new tumor is identified as benign or malignant – or if you’re a fan of HBO’s Silicon Valley – if the data is a hot dog or not a hot dog.
Supervised Machine Learning algorithms apply what has been learned about data in the past to new inputs using labeled examples to predict future results. For example, in cancer diagnosis, a large amount of patient data is gathered regarding the characteristics of a tumor. Since we know which data inputs indicate a benign tumor and which are a malignant one based on a variety of factors, we could label the data as such. Then by simply knowing the cell density and tumor size of new patient inputs, we could predict if the new tumor is identified as benign or malignant – or if you’re a fan of HBO’s Silicon Valley – if the data is a hot dog or not a hot dog.
Unsupervised Machine Learning – does not rely on labeled data inputs. Rather, the algorithm finds the underlying patterns in the data without prior knowledge. Unsupervised learning is most commonly applied to identify previously unknown patterns in data. This is useful for clustering data and especially useful in anomaly detection which can identify fraudulent transactions, human errors and even cybersecurity attacks.
 Supervised vs Unsupervised for Anomaly Detection
Supervised vs Unsupervised for Anomaly Detection
A supervised model “learns” by repeatedly comparing its predictions, given a set of inputs, against the “ground truth” label (the reality you want the model to predict) associated with those inputs. It then adjusts parameters such that the model’s predictions become more accurate. The model is essentially memorizing the categories of the input/output combinations. The goal is to have a model that makes good predictions against both the training data it has already seen as well as the future data that is yet to be seen.
In this way, the model learns a generalized way to recognize patterns within the data on which it’s been trained. In most contexts, this is exactly what is desired, but the corollary is that these supervised models do not perform well in unusual circumstances, especially . in the face of inputs that are dissimilar from that on which they’ve been trained. In human terms – if the security guards have been trained to recognize only faces and not patterns of comings and goings, they’re not going to recognize whether “Bob” coming into the office on a Tuesday is an anomaly or not. Because they have only been trained to know Bob’s face and not Bob’s working patterns, they will not raise an alert.
 This is a key reason why supervised models are not typically used for anomaly detection. Mathematically, the supervised model is trying to determine the probability of an intrusion given a specific input vector whereas the unsupervised model is merely trying to determine the probability of seeing that specific input vector. When using an unsupervised model, probabilities below a determined threshold are flagged as anomalies.
This is a key reason why supervised models are not typically used for anomaly detection. Mathematically, the supervised model is trying to determine the probability of an intrusion given a specific input vector whereas the unsupervised model is merely trying to determine the probability of seeing that specific input vector. When using an unsupervised model, probabilities below a determined threshold are flagged as anomalies.
NLP N-Grams: A Case Study in Pattern Recognition
Natural Language Processing (NLP) is technology used to aid computers in understanding natural human language. It is used in devices such as Amazon’s Alexa and Apple. NLP relies on machine learning to derive meaning from human words, their sequences, the patterns they create together and their varying frequencies. For example, “See Jane Run” is a common pattern in English, where “Jane Run See” is not so common. A machine learning algorithm will churn through the data and learn that “See Jane Run” is common, where it may never see “Jane Run See”. If it ever does, that sequence can be identified as an anomaly.
We experimented using this same N-Gram approach for intrusion detection on an HPE NonStop server. The goal was to profile a system and identify normal behavior in order to be able to quickly detect anomalous activity, which then can be further analyzed for context. Detection methods based on n-gram models have been widely used for the past decade.
Using a sample data set of 2.2 million XYGATE Merged Audit events, we identified a vocabulary of 31 unique operations. (READ, RUN, WRITE, STOP, GIVE etc). 31% of unique user sessions contained 3 or more command operations during the session. We identified 359 unique 3-gram sequences out of a possible 29,791 combinations. For example, we frequently saw “READ+WRITE+WRITE” in a sequence pattern.
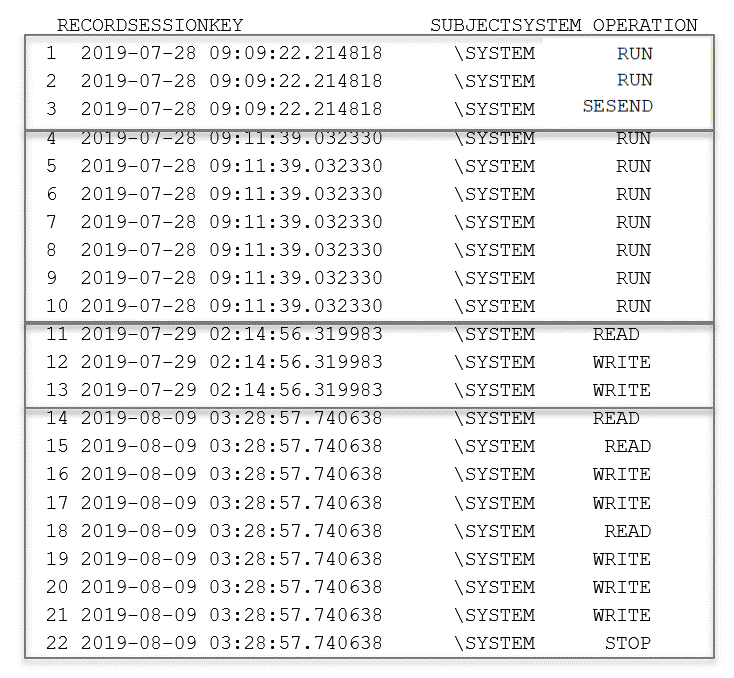
We also expanded our experiment to 4-gram operations. We identified 797 unique 4-gram operations in the same data out of a possible of 923,521 combinations. To put this in context, over 99% of the possible sequence patterns in a 4-gram could conceivably be an anomaly or indicate a system compromise.
Without machine learning algorithms, alerting on security incidents mainly relies on static rules within your alert system. For example, if a user attempts to read a secured file they don’t have access to, an alarm is generated. This method becomes unsustainable as the data gets more voluminous and patterns grow more complex. You would need to program every single pattern and variation to accurately generate alerts on suspicious behavior. Using machine learning, your security-related data can be used to train algorithms to identify anomalous patterns so there isn’t a need to rely on programming for every single situation.
For HPE NonStop servers, the XYGATE Suite of products are able to ingest and generate the data necessary for analytics. It is important to not only generate data, but collect and store it using XYGATE Merged Audit. XYPRO’s newest analytics solution, XYGATE SecurityOne (XS1)is the only solution in the market that ingests NonStop security data, identifies anomalous patterns and raises alerts based on the context of the incident pattern detected.
Referring back to a previous article: “Proactive Security and Threat Detection – it’s not That SIEMple”, we projected the ROI over a three year period for a large, US financial institution with a multi-node NonStop environment. Investing in analytics for investigating “in flight” activities with real-time correlation and the proper contextualization, can free up nearly 80% of the security-related resources. What could a similar investment do for you?
The Bottom Line
Financial Analysis/Cost Savings
| Benefit | Year 1 | Year 2 | Year 3 | TOTAL |
| Compliance | $172,800 | $177,984 | $183,324 | $534,108 |
| Risk Reduction | $215,338 | $215,338 | $215,338 | $646,164 |
| Security Ops Improvements | $66,560 | $68,557 | $70,614 | $205,731 |
| Threat Intelligence Savings | $47,600 | $49,028 | $50,499 | $147,217 |
| Total Benefits | $502,298 | $510,907 | $519,775 | $1,533,220 |

Steve Tcherchian, CISSP, PCI-ISA, PCIP is CEO of XYPRO Technology, a leading provider of mission-critical cybersecurity solutions that protect the digital backbone of industries worldwide. With over 20 years of experience, Steve brings a unique blend of technical expertise, strategic vision, and a customer-first approach that has transformed XYPRO into a top-tier cybersecurity provider, driving record growth and accelerated adoption of its threat detection and compliance solutions across diverse sectors.
A passionate advocate for cybersecurity, Steve is dedicated to demystifying the complexities of the industry and sharing actionable insights on global stages as a sought-after speaker. His contributions extend beyond the podium: as a former member of the ISSA CISO Advisory Council, the X9 Security Standards Committee, the Forbes Tech Council, and as a patent holder, Steve has shaped pivotal cybersecurity standards and innovations that safeguard the world’s most critical workloads.